In the practical application of machine learning to any problem, we will inevitably encounter an essential concept: Hyperparameter Optimization. You might be wondering, “What on earth are hyperparameters, and why should I care about optimizing them?” Well, let’s break it down in the simplest way possible.
What Are Hyperparameters?
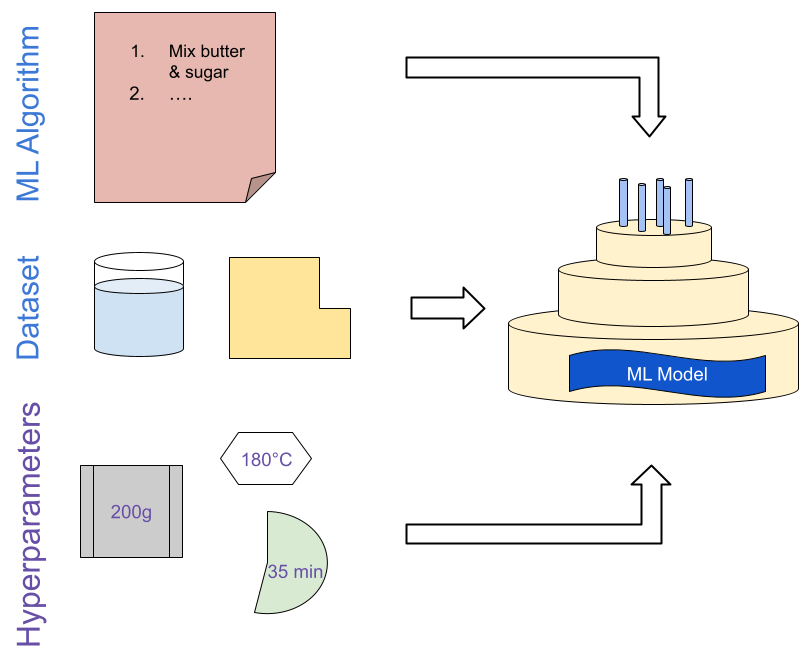
Think of hyperparameters as the settings or instructions you give to an ML model before it can start learning. Imagine you’re building a model as if you were baking a cake. We have to decide which recipe to follow (i.e. which ML algorithm to use) and which ingredients to use (i.e. the data to train the model on). The hyperparameters decide how exactly the ingredients are used in the recipe: the same recipe will need different amounts of liquid if we switch out the flour, more or less sugar depending on the fruits we use and different baking temperatures for different levels of moisture. Even with a good recipe and delicious ingredients, these small decisions and adjustments will decide whether you end up with an impressive cake or a disappointing mess:
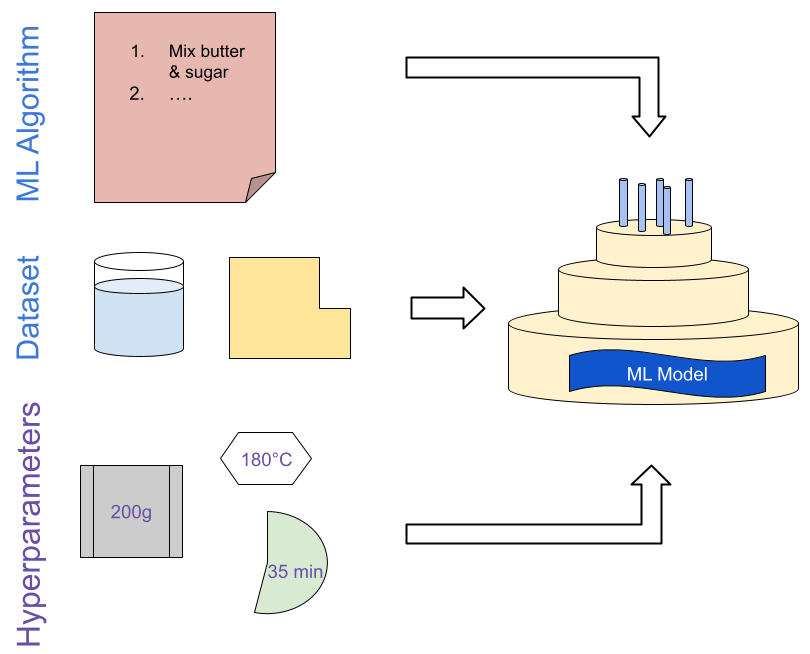
If we apply this logic to machine learning, we have different ML algorithms such as the Adam optimizer and different datasets like ImageNet for which we need to make adjustments. Examples of values that need adjusting in ML training are data preprocessing methods, the learning rate, or batch size. Getting these values right will ensure the algorithm is tailored to the dataset and can produce a well-performing ML model.
Why Optimize Hyperparameters?
Using our cake analogy, what happens if you add too much flour or bake it at the wrong temperature? The cake might turn out dry, burnt, or just plain inedible. Similarly, in ML, if your hyperparameters are off, your model might not perform well: the accuracy might not improve, fluctuate a lot during training and the result will not be useful in practice.
Optimizing hyperparameters is like tweaking your cake recipe until it’s perfect. Unfortunately, just like developing baking recipes, this is no small feat. As ML algorithms typically have several important hyperparameters and each can take a range of values, simply guessing good hyperparameter configurations can be tedious and error-prone, even for seasoned experts. It can involve training dozens, hundreds or even thousands of different versions of your model before seeing any meaningful improvement. Therefore the best course of action is to use optimization algorithms that can automatically find good hyperparameter configurations for you.
How Can We Automate Hyperparameter Optimization?
Optimizing hyperparameters involves testing different combinations to see which ones work best. Using an optimization algorithm can make this process a lot faster and more reliable than doing it by hand. There are many options for hyperparameter optimization algorithms, but most hyperparameter optimization algorithms are based on a combination of black-box optimization and efficient evaluation strategies.
Black-Box Optimization For Hyperparameters
Black-box optimization means the optimization algorithm we use to find good hyperparameters is only receiving the final outcome of each hyperparameter configuration in order to improve; no gradients, no additional information of any kind. This means we get an optimization loop like this:

The optimizer will suggest one or more hyperparameter configurations which we try for our chosen ML algorithm & dataset. The result (an accuracy or a loss) is told back to the optimizer so it can choose better configurations in the next round. In contrast to techniques such as randomly sampling hyperparameter configurations to try, black-box optimizers can improve over time and produce better results. Examples for black-box optimization algorithms include Bayesian Optimization and Evolutionary Algorithms.
Making Hyperparameter Optimization More Efficient
Trying out all of these hyperparameter configurations is expensive – that is why AutoML researchers have devised many different strategies for efficiently determining how good a hyperparameter configuration is. One of the simplest ideas is called Successive Halving: we ask the optimizer for many configurations in the beginning, but only partially execute each configuration. This can mean only using a small portion of the full dataset or training for a short amount of time. Then we discard the bad half of configurations we tried and instead spend more time on the ones we saw performed well. Visualized, it looks like this:

There are of course variations on this idea and many more that contribute to the efficient execution of black-box hyperparameter optimization. The best examples of these can be found in state-of-the-art hyperparameter optimization tools like our own SMAC3.
Why Reporting Hyperparameter Optimization is Important
Once you’ve found the best hyperparameters, it’s crucial to report them and also how you found them in the first place. Here’s why:
1. Reproducibility: If someone wants to recreate your amazing cake, they need your exact recipe. Similarly, sharing your hyperparameters allows others to replicate your model’s success. Moreover, if someone wants to adapt your recipe to a different domain, e.g. a different dataset, sharing your hyperparameter optimization process enables them to easily apply your method.
2. Transparency: Sharing your hyperparameters and optimization pipeline shows the full quality of your work. It helps others trust that your model’s performance is legitimate and not just a lucky fluke. Without sharing your full process, it is hard to judge your results fully.
3. Improvement and Comparison: Other researchers can learn from your work and maybe even improve it. If everyone shares their hyperparameter choices and how they made them, the whole ML community can benefit and advance faster. It does not only help other ML practitioners by recommending well-performing ways of finding good hyperparameter configurations, it also sends a signal to the AutoML research community about what works in practice and what needs improvement.
Hyperparameter optimization might sound technical, but it’s just about finding the best settings for your ML model, much like perfecting a cake recipe. And just like when baking a cake, the best course of action is to rely on experts, i.e. automated hyperparameter optimization methods, in order to save time and resources. Reporting these settings is like sharing your recipe with others. It helps everyone understand, trust, and build upon your work. So, next time you bake a cake or build an ML model, remember the importance of getting those ingredients just right and sharing your recipe with the world!
Comments are closed