Highlight: ARLBench provides a standardized AutoRL benchmark by combining JAX-powered implementations with representative subsets, making high-performance AutoRL research accessible.
- Speed: Delivers up to 10x faster evaluation than standard libraries, using JAX-based training and statistically selected environment subsets.
- Flexibility: Supports static, multi-fidelity, and dynamic HPO (like PBT) through a Gymnasium-like interface with full checkpointing capabilities.
- Validity: Uses a massive dataset of 100,000+ runs to prove that its environment subsets accurately represent the global RL task space.
- Key Insight: RL-specific HPO benchmarks contrast sharply with supervised learning and are therefore highly desirable; standard “off-the-shelf” optimizers can struggle against Random Search on RL’s rugged landscapes.
Check out the GitHub repository.
Hyperparameter optimization (HPO) is one of the main obstacles to reliable reinforcement learning (RL). Modern RL algorithms expose large, highly sensitive configuration spaces, and their performance varies widely across environments and random seeds. Despite progress in automated RL (AutoRL), empirical evaluations of HPO methods remain expensive, fragmented, and difficult to compare. ARLBench addresses this problem by introducing an efficient and standardized benchmark for HPO in RL that substantially reduces computational cost while maintaining a representative comparison of HPO methods.
What makes HPO for RL different from Supervised Machine Learning?
In contrast to supervised learning, HPO in RL faces non-stationary training dynamics, rugged optimization landscapes, and high variance across seeds. Small changes in hyperparameters can lead to catastrophic failure, and good configurations rarely transfer between environments. As a consequence, most HPO methods are evaluated on a small number of tasks with limited configuration spaces, making it difficult to assess generality or establish meaningful baselines. ARLBench is designed to provide a common ground for evaluating AutoRL methods under realistic conditions.
How does ARLBench address this?
ARLBench is a benchmark framework built specifically for HPO in RL. It combines highly optimized JAX-based implementations of DQN, PPO, and SAC with a flexible interface that supports static, multi-fidelity, and dynamic hyperparameter optimization. The framework is complemented by a systematic subset selection strategy for environments and a large-scale meta-dataset capturing hyperparameter landscapes across algorithms and domains.
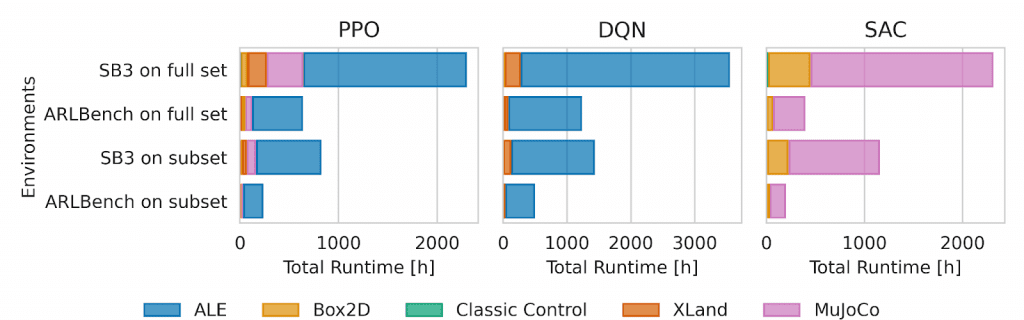
A central goal of ARLBench is efficiency. Compared to commonly used RL libraries, JAX implementations yield substantial speedups, and using representative environment subsets further reduces runtime. Together, these design choices lower the cost of evaluating HPO methods by approximately an order of magnitude.
The AutoRL Environment Interface
At the core of ARLBench lies the AutoRL Environment, which serves as the interaction point between an HPO method and RL training. The interface is inspired by Gymnasium and allows an optimizer to specify both a hyperparameter configuration and a training budget at each optimization step. ARLBench then executes the corresponding RL training run and returns optimization objectives such as evaluation return or runtime, along with optional state information such as gradients or losses.
Furthermore, this interface supports dynamic HPO. Training state, including network parameters and optimizer state, can be checkpointed, restored, or duplicated. This enables population-based methods, adaptive schedules, and meta-gradient approaches to be evaluated in a unified and reproducible manner.

Selecting Representative Environments
Efficiency alone is not sufficient for meaningful benchmarking. ARLBench therefore addresses the question of which environments best represent the broader RL task space. To this end, we conduct a large-scale pre-study in which hundreds of hyperparameter configurations are evaluated across diverse environments spanning the Arcade Learning Environment (ALE), Classic Control, Box2D, Brax robotics, and XLand grid worlds.
Using these data, ARLBench applies a regression-based subset selection method that identifies small sets of environments whose performance rankings are highly predictive of average performance across all environments. The resulting subsets contain five environments for PPO and DQN and four for SAC.
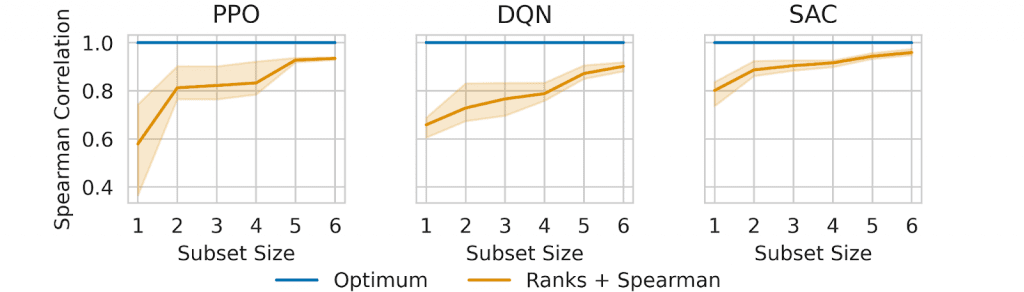
Preserving HPO Landscape Properties
A key concern with environment reduction is whether it distorts the underlying HPO problem. ARLBench addresses this by comparing hyperparameter landscapes on the full environment sets and their corresponding subsets. Return distributions over randomly sampled configurations show that the subsets preserve both easy and adversarial regimes, including skewed distributions and sharp performance transitions.
Analyses of hyperparameter importance further confirm that the number and structure of influential hyperparameters remain largely unchanged. In addition, evaluations of several HPO optimizers—random search, population-based training, SMAC, and SMAC with Hyperband—show consistent relative performance rankings on subsets and full sets.
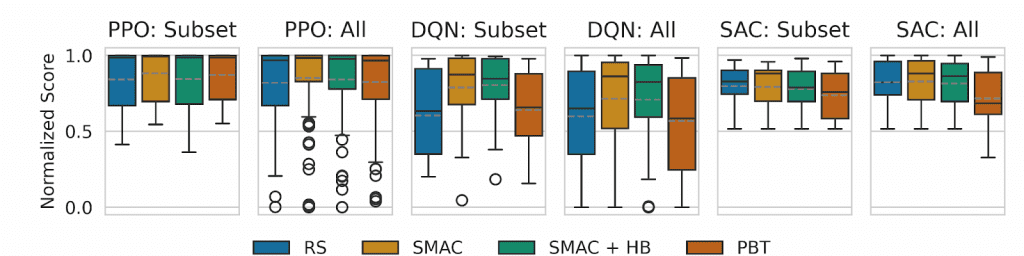
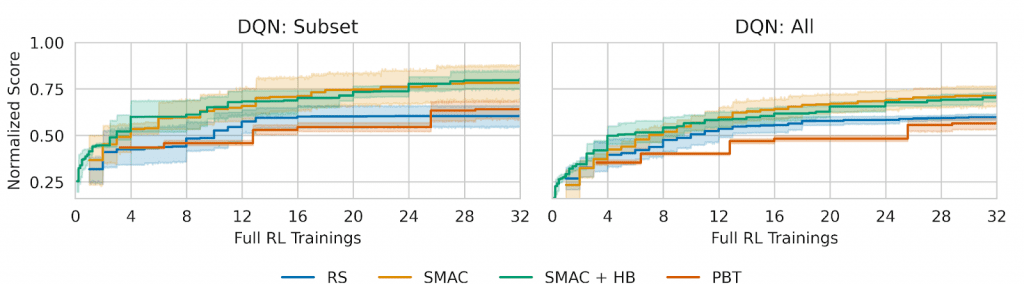
Results obtained with ARLBench reinforce the view that HPO in RL is fundamentally challenging. Hyperparameter landscapes are often highly irregular, and state-of-the-art optimizers do not consistently outperform random search. This behavior contrasts sharply with supervised learning and highlights the need for RL-specific HPO research rather than direct transfer of existing methods.
Outlook
ARLBench provides an efficient, flexible, and empirically grounded benchmark for hyperparameter optimization in reinforcement learning. By combining fast implementations, representative environment subsets, and a large public dataset, it enables rigorous, comparable evaluation of AutoRL methods at a fraction of the cost required previously. As such, ARLBench lays the groundwork for more systematic progress in automated reinforcement learning research.
ARLBench currently focuses on model-free RL algorithms and standard environment benchmarks. While this scope already covers a large portion of RL research, future extensions are planned to include richer algorithm variants, policy generalization, and surrogate modeling for dynamic HPO. Despite remaining computational costs, ARLBench prioritizes realism and flexibility over purely tabular benchmarks.
Full paper: arxiv.org/abs/2409.18827
GitHub: github.com/automl/arlbench
Dataset on Hugging Face: huggingface.co/datasets/autorl-org/arlbench
Comments are closed