
Authors: Carolin Benjamins, Helena Graf, Sarah Segel, Difan Deng, Tim Ruhkopf, Leona Hennig, Soham Basu, Neeratyoy Mallik, Edward Bergman, Deyao Chen, Francois Clément, Matthias Feurer, Katharina Eggensperger, Frank Hutter, Carola Doerr, Marius Lindauer
carps in a nutshell (tl;dr)
- framework for benchmarking N optimization methods on M benchmarks
- lightweight interface between HPO optimizers and benchmarks
- many included HPO tasks from different scenarios BB, MF, MO, MOMF
- subselections for scenarios to allow for efficient benchmarking
- tutorials are available

Try it yourself! 🤗

Find the paper here 🔍
Developing HPO needs Benchmarking
When benchmarking a new optimizer, we have three main challenges. First, we need to select appropriate benchmark tasks among many and appropriate baselines. Second, the benchmarks and baselines need to be integrated in an experimental setup. Third, often, in our research flow, we develop new benchmarking setups from scratch for each project, wasting time and reducing comparability.
carps is a framework for benchmarking
Therefore, we propose carps, which aims to alleviate the experimental process. carps provides a comprehensive experimentation pipeline where defining and running experiments, logging and analysis, is made easy. In addition, the interface glueing together HPO optimizer and benchmark is kept as lightweight as possible to facilitate integration of custom optimizers and benchmarks. Moreover, carps offers easy access to 5365 HPO tasks from 6 benchmark collections and 28 variants of 9 optimizer suites. Because this number of tasks is huge, we also offer subselections for development and testing for different optimization scenarios, namely black-box, multi-fidelity, multi-objective, and multi-fidelity-multi-objective. This allows quick development and evaluation of new optimizers on a representative and informative set of benchmarks.
Interface of carps
carps glues optimizers and benchmarks together via a lightweight interface.
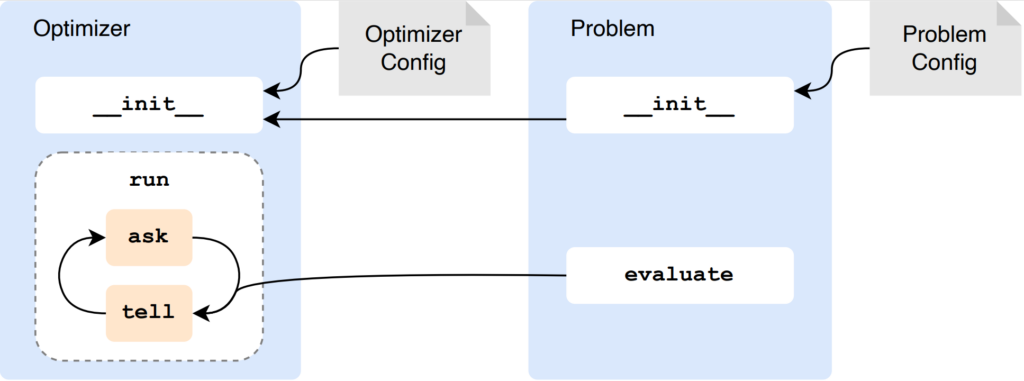
The optimizer should support ask and tell, but there is also a solution if not. Optimizer and problems are defined by configuration files. carps can log either to files or to a database.
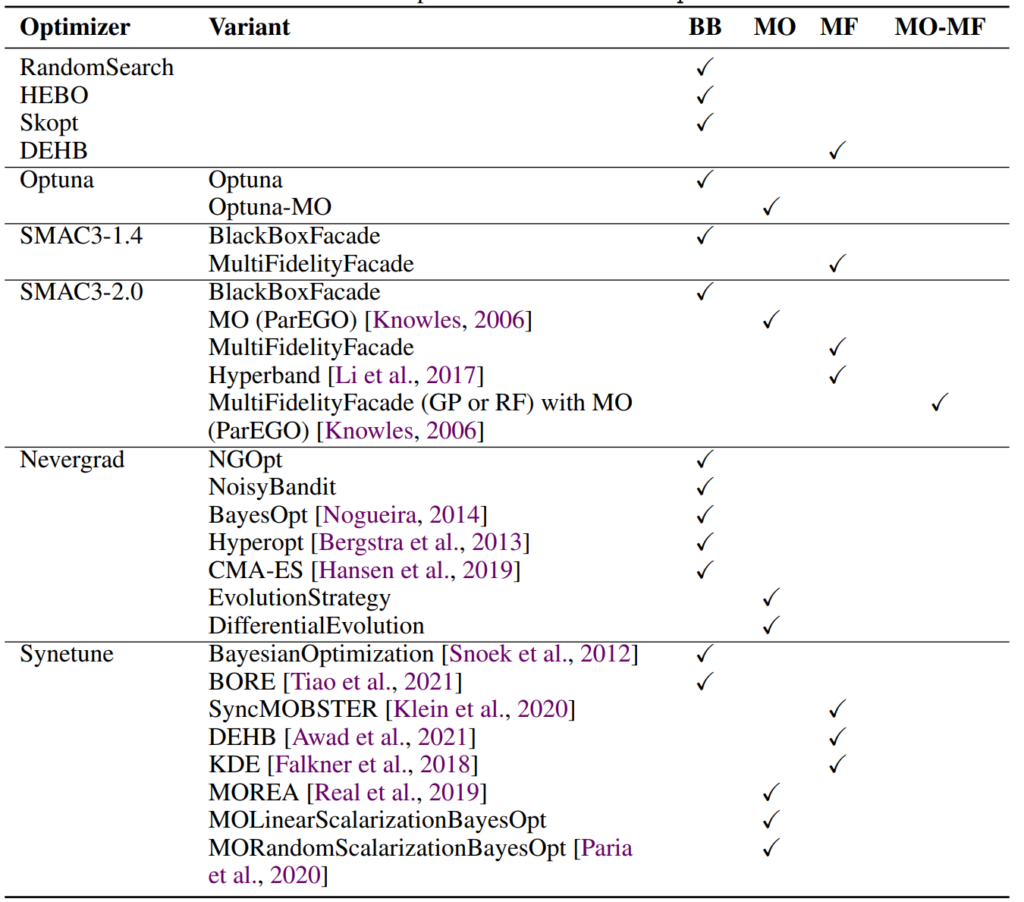
carps includes many optimizers
carps includes many HPO benchmarks
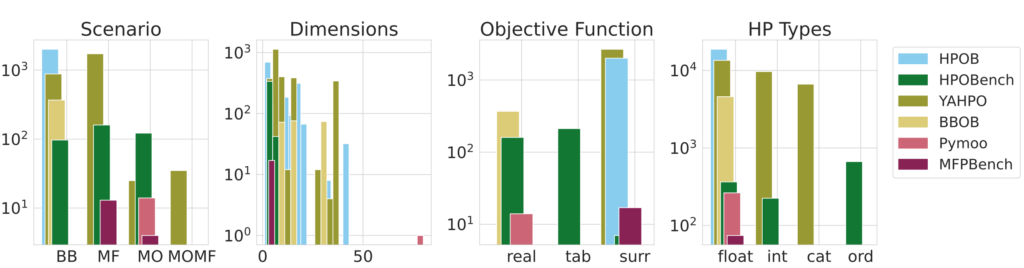
In total, 5365 tasks are there at the moment! Included benchmarks are:
- HPOB [Pineda Arango et al., 2021]
- HPOBench [Eggensperger et al., 2021]
- YAHPO [Pfisterer et al., 2022]
- BBOB [Hansen et al., 2020]
- Pymoo [Blank et Deb, 2020]
- MFPBench [Mallik et al., 2023]
carps provides representative benchmark subselections
In order to reduce computational costs and avoid bias from specific types of problems, we offer subselections. Below is the subselection visualized for the black-box scenario.
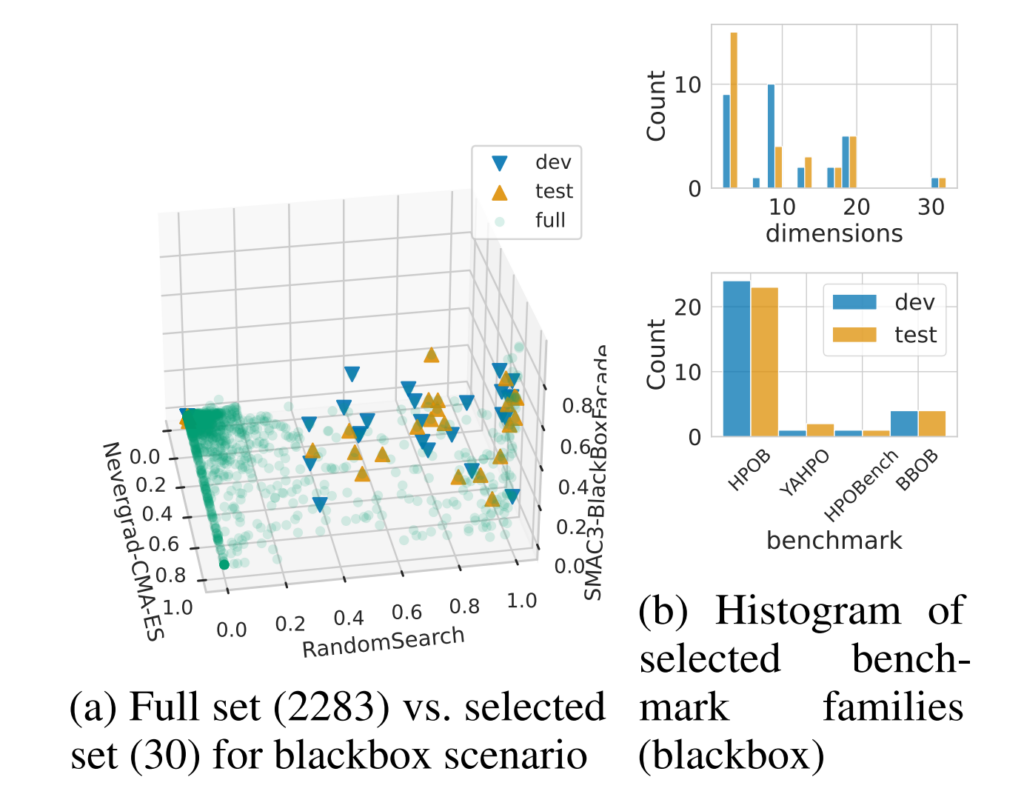
carps subselects via optimizing star discrepancy
We can abstract the subselection as an optimization problem where, from a point cloud, we want to select those k points that best cover the space spanned by the point cloud. We use performance data to define the points because this can hint at the difficulty of tasks for set of representative optimizers. The approach consists of three main steps:
- Run three optimizers with different search behavior on all tasks of one scenario (e.g., Random Search, CMA-ES, SMAC3-BlackBox on all black box tasks)
- Span performance space with performance tuple
- Subselect those k points which describe the space best via minimizing the star discrepancy [Clément et al., 2022; Clément et al., 2024]
carps makes experimenting and analysis easy by providing the tools
Besides running experiments, carps also has plotting and analysis capabilities. We can plot the ranks with critical difference, performance over time (which is normalized), the final performance on each problem per optimizer as a heatmap, the correlation matrix between optimizers, as well as final performances as a boxplot and violinplot.
Results on blackbox subselection
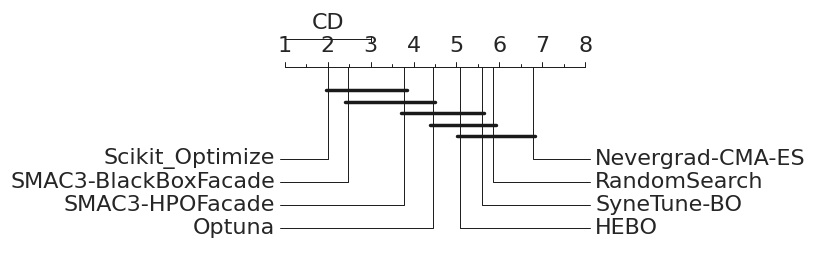
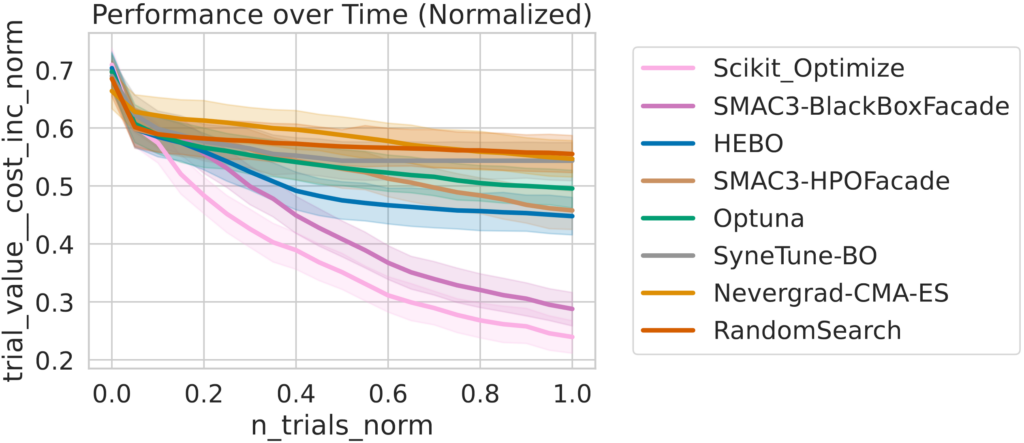
Links: [Paper | GitHub]
Comments are closed