Authors: Carolin Benjamins, Gjorgjina Cenikj, Ana Nikolikj, Aditya Mohan, Tome Eftimov , Marius Lindauer
TL;DR: In Dynamic Algorithm Configuration (DAC) [Biedenkapp et al., 2020] we aim to improve generalization of Reinforcement Learning (RL) agents as dynamic algorithm configurators. For this, we subselect representative instances to train the RL agent on. Our main insight is that careful selection improves generalization on an unseen test set.
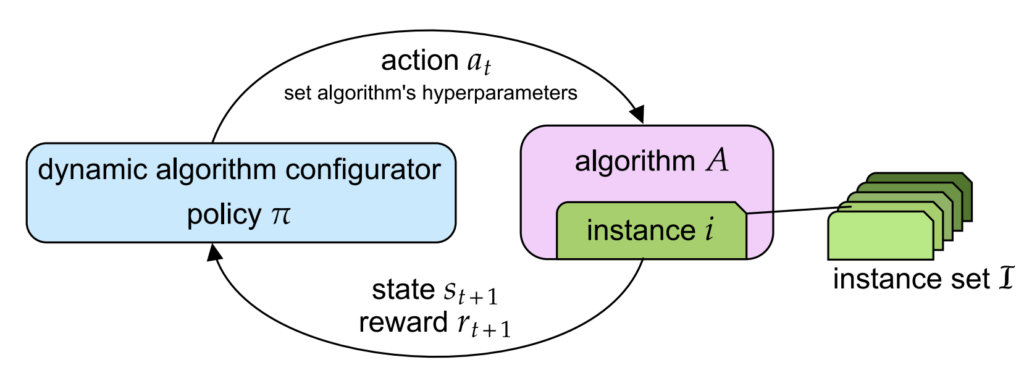
Background: Dynamic Algorithm Configuration
Dynamic Algorithm Configuration (DAC) [Biedenkapp et al., 2020] is a technique aimed at dynamically adjusting the hyperparameters of an algorithm in response to different instances or tasks. Unlike static configuration, which sets hyperparameters once before execution, DAC allows for continuous adjustments during runtime. Consider the learning rate: The traditional practice was to fix this at the start of the training, which was succeeded by a schedule of different learning rates as the algorithm trains. DAC takes this a step further by learning how to set the learning rate as the algorithm trains. This adaptability is crucial for optimizing performance across a diverse range of problems, making algorithms more robust and efficient.
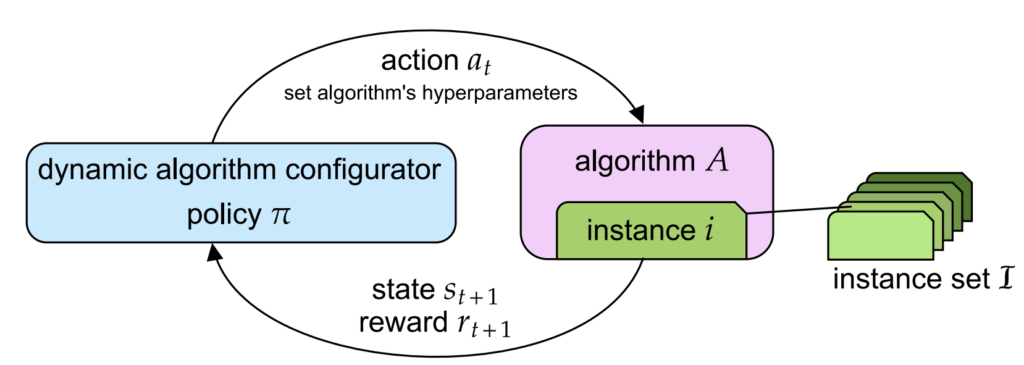
Problem Setting: Improve generalization of DAC configurators
A major objective of DAC is to perform well across many tasks. However, this generalization ability is not easy to achieve, even when applying RL-based DAC to a large set of different tasks. We hypothesize that a bias in training instances affects the generalization capabilities of RL agents. In this paper, we explore the selection of a representative subset of training instances to mitigate overrepresentation, aiming to improve the generalization performance of RL agents for DAC.
To capture the agent’s dynamic behavior and to select instances that improve generalization, we construct meta-features based on the trajectories of actions and rewards. We address the challenge in generalization by selecting a representative subset of instances for training, which should better capture the dynamics of the broader instance space.
![]()
Our approach involves the following steps:
- Training an RL Agent: Initially, we train an RL agent on the full set of training instances.
- Generating Rollout Data: We evaluate the trained agent on the training set to produce rollout trajectories, which include the actions taken and rewards received.
- Instance Selection with SELECTOR: Using the generated rollout data, we apply the SELECTOR [Cenikj et al., 2022] framework to select a representative subset of instances.
- Retraining on Selected Instances: Finally, we retrain the RL agent on the selected subset of instances to obtain a policy that generalizes better to new test instances.
Empirical Evaluation on DACBench
We empirically evaluate the RL agent on the Sigmoid and CMA-ES benchmarks from the DACBench library [Eimer et al., 2021]. Our key findings include:
- Improved Generalization: Training on the selected subset of instances led to better generalization performance compared to training on the full instance set.
- Performance Comparison: The RL agent trained on the selected instances performed better than instance-specific agents (ISAs) and agents trained on random subsets of instances.
- Diversity in Training: The selected instances captured diverse dynamics, which helped in escaping potential local minima in the policy space.
For the Sigmoid benchmark, the SELECTOR with the Catch22 representation of actions and rewards proved most effective. For the CMA-ES benchmark, the combination of Dominating Sets (DS) method with Catch22 features provided the best results.
Conclusion
Our work highlights the potential of instance selection in enhancing the generalization capabilities of RL for DAC. By carefully selecting representative training instances, we address the issue of overrepresentation and demonstrate improved performance on unseen instances. This approach offers a scalable solution that can adapt to the complexities of dynamic algorithm configuration using RL.
For researchers and practitioners in machine learning and reinforcement learning, our paper provides valuable insights into improving the generalization performance of RL agents in dynamic algorithm configuration. We encourage you to read the full paper to explore the detailed methodology, experimental setup, and comprehensive results that demonstrate the efficacy of our approach. The code and data used in this study are available at our GitHub repository, allowing you to replicate and build upon our work.
Comments are closed