by Sasa Mladenovic, Marius Lindauer and Carola Doerr
Data preparation, though essential for effective machine learning, remains a manual and time-consuming process. It is often overlooked in AutoML, which tends to rely on data already being fit for machine learning. Our paper “Automated Data Preparation for Machine Learning: a Survey” explores how to automate this vital step, and expand the reach of automation to cover the ML pipeline end-to-end: from raw data to quality model predictions. To our knowledge, the survey is the first of its kind to focus on this topic. This post provides a view into its main takeaways.
Historically, the machine learning field has been dominated by model-centric approaches, focusing on optimizing algorithms, models, and hyperparameters. The same holds true for AutoML. Yet, it is a common observation that data quality frequently presents a bottleneck in real-world ML applications, where data is typically imperfect, or dirty. Recognizing this setback and the potential performance upside of optimizing data, the rising data-centric AI paradigm shifts the focus from refining the model to enhancing the data.
In an effort to bridge the gap between data-centric AI and AutoML, we investigate the prospects of automating data preparation. Beyond considering its extent in existing AutoML systems, we find a multitude of approaches to automating the process, consisting of both fully automated and semi-automated methods. They present various underlying methodologies, each with their own advantages and limitations.
Before diving into those, let us zoom in on data preparation in the context of ML, and the challenges that its automation entails.
Data preparation in ML

Data science allows us to extract insights about the world around us through data-driven approaches. Within the larger data science workflow, the machine learning pipeline, as we consider it, can be subdivided into two overarching components: data preparation and modeling. Data preparation involves applying a sequence of transformations to raw data to ensure its usability and optimize result quality for a given ML model. Modeling encompasses selecting the most adequate machine learning algorithm and tuning its hyperparameters for the best possible outcomes. These two components are closely intertwined: data preparation can be tailored to a chosen model; simultaneously, the state of the data influences the best choice of model. Both steps are essential for good results, in terms of model quality as well as time/memory performance.
Data transformations
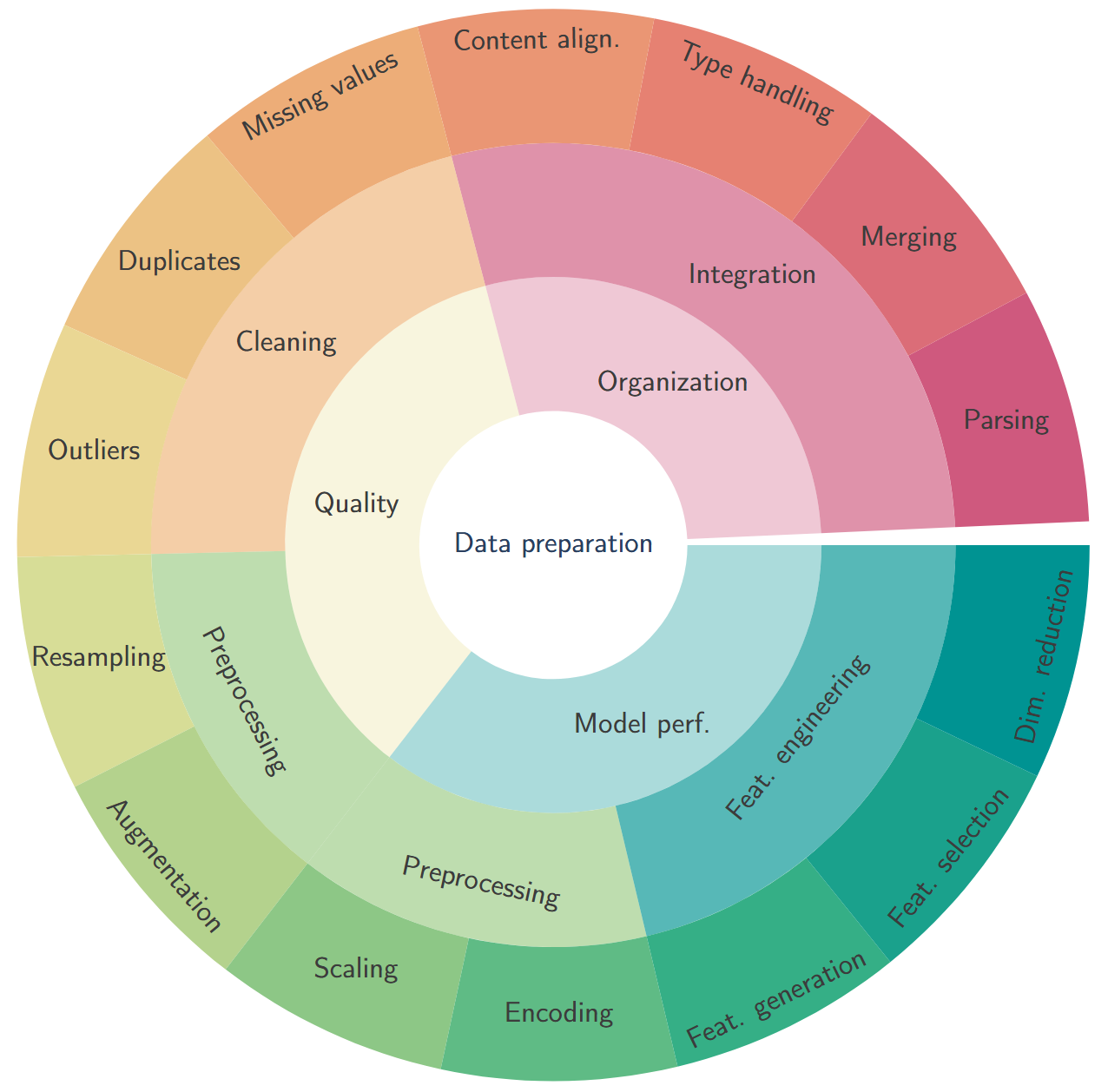
To help navigate the plethora of available data transformation choices, we propose a taxonomy where we structure them along three levels of abstraction:

- Purpose – what they aim to achieve: data organization, data quality, and model performance;
- Function – how they achieve it: data integration (under organization), data cleaning (under quality), data preprocessing (under quality and model performance), and feature engineering (under model performance);
- Category – grouping transformations that address the same problems or improve the same aspects of the data. These categories include parsing, merging, type handling, content alignment (under data integration); missing values, duplicates, outliers (under data cleaning); resampling, augmentation, scaling, encoding (under data preprocessing); and feature generation, feature selection, dimensionality reduction (under feature engineering).
Data pipelines
Data preparation is typically done by means of a pipeline of data transformations that are applied to the data. The design of a data pipeline is highly dependent upon the data format and contents, the machine learning task to perform, and the learning algorithm selected for the task. For a given ML algorithm, the main considerations in designing this pipeline are:
- Transformation selection – choosing data transformations to apply and sometimes which features to apply them to;
- Transformation ordering – architecturing the sequence of transformations;
- Hyperparameter optimization – setting transformation parameter values where applicable.

Since the impact of these choices cannot be assessed without empirical evaluation, we can regard pipeline design as a black-box optimization problem whose search space lies in the possible combinations along those three dimensions.
Data preparation in AutoML
To assess the state of data preparation in AutoML, we explore the data transformation categories covered by different AutoML solutions, as well as their decision processes. We compile a collection of relevant AutoML systems, separating them in accordance with the way they handle data preparation: those with static data preparation (preset or rule-based) and those with optimized data pipelines.
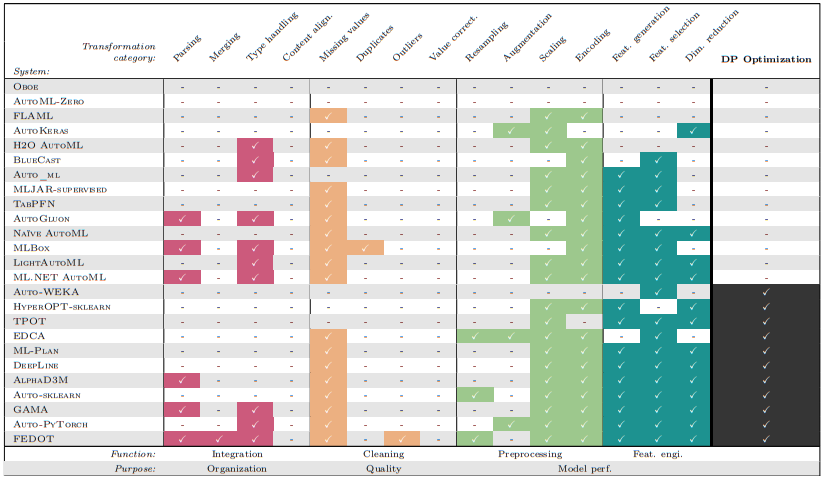
Our analysis demonstrates that automated data preparation in current AutoML systems is largely focused on model performance optimization. Aside from some missing value cleaning to ensure usability, the most frequently present transformations are feature engineering ones, scaling, and encoding, emphasizing the prioritization of model performance. We note a significant lack of transformations centered around data quality and more complex data integration, which reveals a tendency to expect well-formatted data, and rely on the model’s capabilities to overcome other issues.
Semi-automated data preparation
We next examine semi-automated data preparation approaches, which encompass methods that partially automate the data pipeline or fully automate a select part of it.
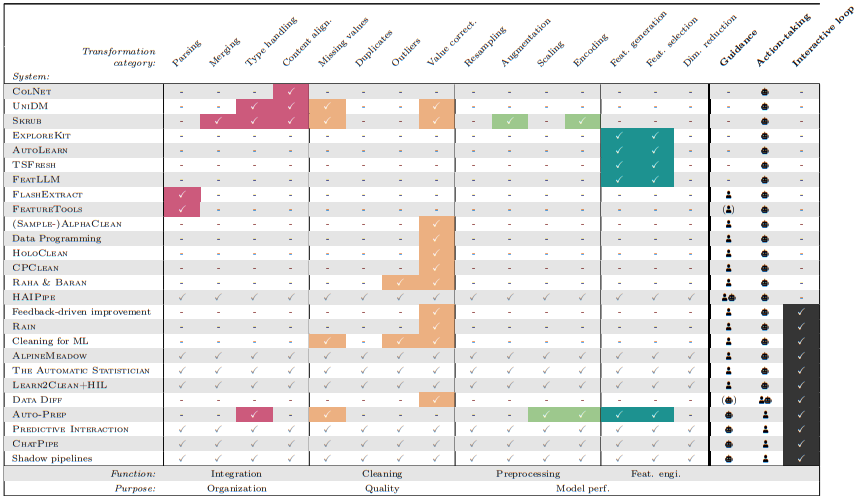
We find an interesting mix of interactive approaches: some where data preparation is handled automatically with guidance from human insights, and others where a human user performs data preparation with the assistance of automated recommendations. This affirms the value of human intervention, in particular for tasks that benefit from analytics and domain knowledge, such as content alignment. Still, the potential role reversal of human and automation between different approaches leaves the door open for automating any aspect of the process.
Automated data preparation
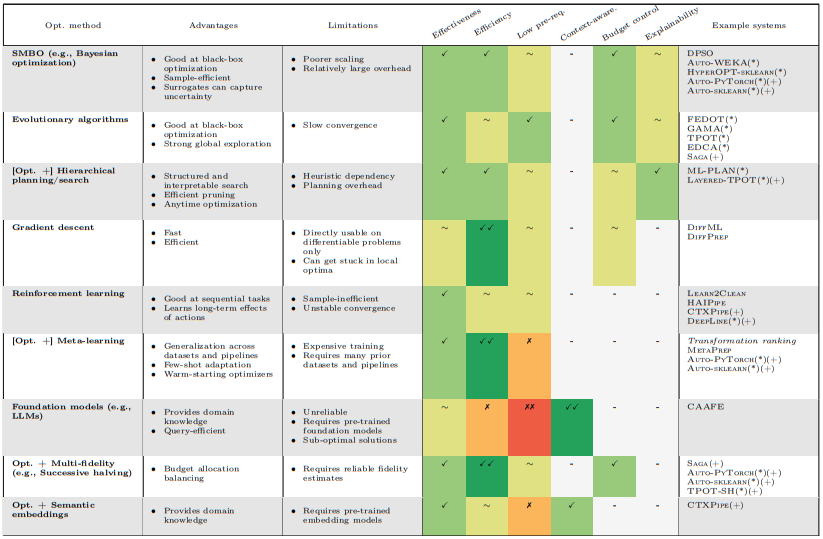
Finally, we turn to fully automated data preparation, reviewing various optimization methodologies proposed for the task. These include reinforcement learning, sequential model-based optimization (SMBO) such as Bayesian optimization, foundation models (like LLMs), gradient descent, evolutionary algorithms, meta-learning, and hierarchical planning, as well as multiple combinations of the above with other methods that enhance their capabilities.
We provide a comparative overview of these approaches, summarizing their advantages and limitations, and rating them across some relevant criteria when making a choice: effectiveness, efficiency, pre-requirements, context-awareness, budget control, and explainability. We include examples of data pipeline optimization systems, or AutoML systems that also optimize data pipelines, that employ these methodologies.
Looking to the future
The main challenge in automating data preparation for ML has consistently been the design of an optimization algorithm for the vast search space of data pipeline configurations that is both efficient and effective. While significant progress has been made in automating the process, substantial challenges still remain. Continued research in these directions, and the eventual complete automation of the ML workflow from raw data to inference, would constitute a profound advancement towards automating data science in an increasingly data-driven world.
Where to learn more?
If this preview has piqued your interest, we invite you to read our full survey paper [LINK TO PREPRINT].
Comments are closed