Authors:
Joseph Giovanelli, Alexander Tornede, Tanja Tornede and Marius Lindauer
Motivation
Hyperparameter optimization (HPO) is a critical aspect of maximizing the performance of machine learning (ML) models. In real-world applications, ML practitioners often face multi-objective (MO) problems, which involve optimizing conflicting objectives such as accuracy and energy consumption. Since there is not a single optimal solution to a multi-objective problem, MO-ML algorithms return a Pareto front, which is a set of models optimized for different tradeoffs of the objectives – for models on the Pareto front, improvement in one objective would worsen another and thus they do not dominate each other. A common example is the trade-off between accuracy and energy efficiency: If you make your model larger, it will hopefully also achieve higher accuracy but at the same time the energy consumption will also increase – obviously, not all models are a reasonable choice in terms of accuracy vs energy consumption.
To optimize for a good approximation of the Pareto front (i.e., a set of non-dominated models), we have to quantify the quality of a Pareto front. However, selecting the appropriate quality indicator to evaluate these Pareto fronts is challenging and often requires deep expertise, which is not necessarily available to all ML users. In fact, different quality indicators can lead to different Pareto front approximations, e.g., more models on one end of the spectrum of the Pareto front vs. more models evenly distributed across the entire Pareto front.
Key Challenges and Insights
To make multi-objective ML and HPO available to users in an easy-to-understand way and without requiring additional technical expertise, we are facing the following challenges:
- Complex Evaluation: Evaluating hyperparameter configurations in MO-ML is non-trivial since it involves assessing the quality of the resulting Pareto front.
- Indicator Selection: There are several indicators to measure Pareto front quality, leading to different Pareto front approximations; but choosing the right one can be difficult for users without detailed technical expertise.
- User Preferences: Users often struggle to map their preferences for Pareto front shapes to specific indicators, leading to suboptimal optimization outcomes.
Proposed Approach

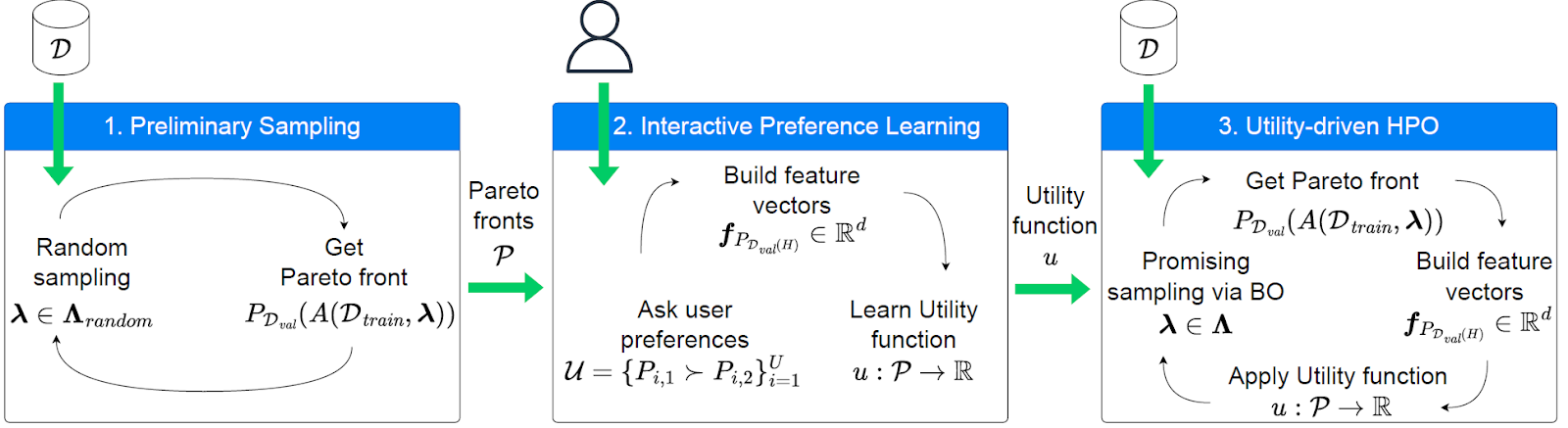
We propose an interactive, human-centered HPO approach that leverages preference learning to tailor the optimization process to user preferences. This method involves:
- Interactive Preference Learning: We sample random configurations and extract Pareto front approximation out of these. By repeating this several times, we can get many exemplary Paretor fronts such that users can provide pairwise comparisons of different Pareto fronts, indicating which they prefer.
- Learning a Quality Indicator: These preferences are used to learn a latent utility function that acts as a customized Pareto front quality indicator.
- Utility-Driven Optimization: This learned indicator is then used in an HPO tool to optimize the hyperparameters of MO-ML algorithms.
Take-aways from the Experiments
We conducted an experimental study focusing on the environmental impact of ML models, showcasing the effectiveness of their approach. Key findings include:
- Improved Performance: The proposed approach led to significantly better Pareto fronts compared to those optimized using an incorrect pre-selected indicator.
- Robustness: Even when users lacked advanced knowledge to select the right indicator, the approach performed comparably to scenarios where advanced users made the right choices.
Conclusion
This paper presents a novel, user-friendly approach to hyperparameter optimization in multi-objective machine learning problems, leveraging interactive preference learning to enhance the optimization process. Our experimental validation underscores the practical benefits of this approach. For a deeper understanding and to explore the detailed methodologies and results, readers are encouraged to read the full paper.
Links [Paper (ArXiv) | AAAI’24]
Comments are closed