When it comes to training Deep Reinforcement Learning (RL) agents, the experience can often be described as “hyperparameter hell” – small changes to learning rate, target update rates, or regularization can flip a run from strong performance to complete collapse. Worse, the knobs that matter can change over training, as previously demonstrated by (TODO: Add autorL landscapes blogpost) – explaining why it is often better to change them during training using schedules, or dynamic algorithm configurations.
But is this instability an inherent property of RL, or is it largely a side effect of how we train RL agents? In this paper, we study hyperparameter landscapes in offline goal-conditioned RL (GCRL) to separate two confounders that are entangled in standard online training: exploration-driven distribution shift, and the learning objective itself, especially whether it relies on bootstrapping. By using offline datasets, we remove the chaotic non-stationarity induced by exploration. That lets us ask a cleaner question: when data quality changes, do different objectives respond in fundamentally different ways?
Why Offline Goal-Conditioned RL?
By focusing on offline datasets, we remove the need for exploration that is common in online RL, and by using a goal-conditioned reward, we remove the correlation between hand-crafted reward functions and hyperparameters previously noted.
GCRL offers rich structure: goal-conditioned value functions obey a quasimetric property. The value function encodes the notion of cost—what is the discounted return from this state. In GCRL, this is inversely proportional to distance: the closer a state is to the goal, the more valuable it is. Crucially, this distance is asymmetric: reaching the goal from a state can be easy while returning is impossible or expensive, and distances compose along trajectories. This induces a structured geometry over the state space that learning algorithms can exploit, rather than treating goal values as independent predictions. Consequently, there have been a line of RL algorithms that do not use TD-Learning and bootstrapping, and instead solve constraint optimization problem (TODO add).
Studying the hyperparameter landscapes of these algorithms against those that use TD-Learning, while doing it on offline datasets, can enable us to disentangle the impact of exploration and objectives to better understand what leads to brittleness in the hyperparameter space
The Core Finding: Hyperparameters can be “Benign”
The most striking result is that in offline settings, RL hyperparameter landscapes are significantly more robust (or “benign”) than commonly reported for online settings. Once an agent has access to a modest amount of expert data (~20%), the “safe” regions for hyperparameters become remarkably wide. However, a strong contrast emerges when comparing how different algorithms handle the same data:
- QRL (Quasimetric Learning): Once it hits the 20% expert data threshold, QRL maintains broad, stable near-optimal regions. If you find a good configuration early, it typically stays good throughout the training process.
- HIQL (Bootstrapped TD-Learning): Even with fixed data, HIQL exhibits “sharp optima” that drift significantly across training phases. A learning rate that is perfect for exploratory data might become a failure as the data quality improves.
We can see how the optimum moves for HIQL (left), while being comparatively stable for QRL (right):
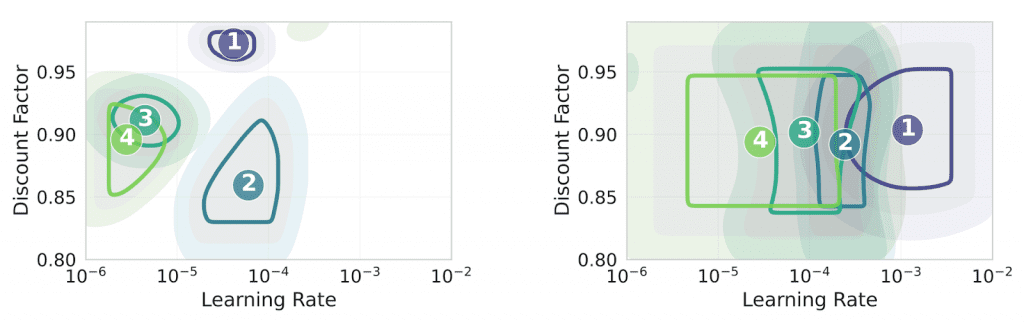
The “Bootstrapping Tax”: What Causes the Drift?
To understand why HIQL drifts while QRL stays stable, we looked at gradient alignment across goals. The signal is clear: HIQL exhibits substantially less aligned gradients than QRL, and alignment correlates with which hyperparameter configurations actually perform well.
The intuition is simple. In goal-conditioned learning, you are effectively solving many related problems simultaneously: one goal per target state (or per goal specification). With TD learning, each goal’s update depends on bootstrapped targets that themselves depend on the current network. If updates for different goals point in conflicting directions, they can partially cancel each other out or amplify noise. As data quality shifts, the balance of these conflicts changes, so the hyperparameters that best manage them also change.
What emerges from this analysis is a potential mechanism for drift: bootstrapping introduces recursive target dependencies that amplify inter-goal update interference. In contrast, representation-based objectives like QRL learn a geometric map of the environment (a quasimetric) without recursive targets, which produces more consistent gradients and, empirically, much wider stability regions.
Which Knobs Actually Matter?
Using fANOVA analysis to quantify hyperparameter importance, the study found that different objectives require very different tuning strategies:
- QRL is a “Single-Knob” Algorithm: After the initial training phase, QRL’s performance is dominated almost entirely by the learning rate. Most other parameters, like the discount factor, have a negligible impact on stability.
- HIQL is a “Multi-Knob” Balancing Act: HIQL’s importance is distributed across a broader set of hyperparameters. Because the “influential knobs” shift as data quality changes, practitioners often have to retune multiple parameters simultaneously to maintain performance.
The figure below shows the perplexity of relative importances, a measure that can be interpreted as the number of hyperparameters that matter, across training progress.

Takeaways for the Practitioner
This research suggests that the extreme sensitivity we’ve accepted as an “RL tax” is actually a choice.
- Objective Design is Your Best Buffer: If you want to avoid constant tuning, representation-based objectives (like QRL) offer much higher stability by default.
- Bootstrapping Requires Maintenance: If your task requires TD-learning, be prepared for your hyperparameter landscape to move. You aren’t just tuning for the task; you are tuning for the current quality of your data.
- Data Quality Matters Early: Even a small injection of expert demonstrations can stabilize an otherwise brittle algorithm, providing a much-needed buffer for hyperparameter selection.
If you want to see more details, take a look at the full paper on arXiv.
Comments are closed